Chronique
L’IA distribuée marque-t-elle la fin du SaaS tel que nous l’avons connu ?
Les choix d'architecture du monde numérique de ces quinze dernières années subissent la nouvelle réalité de l'intelligence artificielle. Cette chronique décrit comment l'IA distribuée implique de repenser le rôle du cloud.


Pendant quinze ans, la transformation numérique des entreprises a reposé sur une idée simple : déplacer les applications vers le cloud, puis les consommer sous forme de services. Le SaaS a profondément changé la manière dont les organisations achètent, déploient et utilisent le logiciel. Il a accéléré l’adoption, réduit les frictions d’infrastructure et imposé un modèle fondé sur l’abonnement, la mise à jour continue et l’accès à distance.
Mais l’intelligence artificielle remet en question une partie de cette architecture. Non pas parce que le SaaS serait condamné à disparaître. Il restera une composante majeure du système d’information. Mais parce que l’IA déplace le centre de gravité de la valeur. La question n’est plus seulement : quelle application utiliser ? Elle devient : où se trouvent les données, où exécuter les modèles, comment orchestrer les agents, avec quelles garanties de coût, de souveraineté, de performance et de contrôle ? C’est ce basculement qui ouvre une nouvelle étape. Après l’ère des applications centralisées, les entreprises entrent dans l’ère de l’intelligence distribuée.
Le cloud progresse, mais l’entreprise reste hybride
Le récit dominant des dernières années était clair : l’avenir de l’IT serait majoritairement cloud. Dans les faits, la réalité est plus nuancée. La migration vers le cloud se poursuit, mais elle ne se traduit pas par la disparition rapide des infrastructures internes. Les grands groupes conservent des datacenters, des clouds privés, des environnements industriels, des systèmes historiques, des plateformes souveraines et des applications critiques qui ne peuvent pas toujours être déplacées facilement vers un cloud public centralisé.
Gartner estime ainsi que, d’ici 2027, 50 % des applications critiques d’entreprise résideront hors des localisations centralisées de cloud public. Ce chiffre confirme une tendance de fond : l’hybridation n’est plus seulement une étape transitoire. Elle devient une condition durable de l’architecture numérique.
L’IA accentue cette dynamique.
Une application SaaS classique enregistre, affiche ou met à jour des données. Un système d’IA les interprète, les contextualise, les croise et agit à partir d’elles. Il doit accéder à des sources multiples : CRM, ERP, bases documentaires, messageries, données industrielles, historiques de maintenance, données clients, modèles métier, capteurs ou systèmes de conformité.
Or ces données ne sont pas toutes dans le cloud. Elles sont dispersées dans l’organisation. Certaines sont sensibles. Certaines sont réglementées. Certaines sont trop volumineuses pour être déplacées en permanence. D’autres doivent être traitées au plus près de leur lieu de production pour des raisons de latence, de coût ou de continuité opérationnelle. C’est là que l’architecture change. Le modèle historique consistait à faire remonter les données vers l’application. Le modèle émergent consiste de plus en plus à rapprocher l’intelligence des données.
L’intelligence se déplace vers les données
La première vague de transformation numérique consistait à déplacer les applications vers le cloud. La suivante consiste à déplacer l’intelligence vers les données. Demain, un agent IA d’entreprise ne se contentera pas d’interagir avec une seule application. Il pourra consulter un CRM, analyser des documents SharePoint, interroger un ERP, accéder à une base métier interne, exploiter un modèle open source hébergé localement et déclencher un processus dans une plateforme cloud.
Dans ce scénario, aucun système unique ne détient l’ensemble de la donnée. Aucun fournisseur ne détient l’ensemble de l’intelligence. La valeur vient de la capacité à orchestrer des modèles, des données, des règles métier et des permissions dans des environnements multiples. Cette évolution est particulièrement visible dans l’industrie, la santé, l’énergie, la finance, les infrastructures critiques ou les collectivités. Dans ces secteurs, il est rarement possible de tout centraliser. Les contraintes de confidentialité, de souveraineté, de latence, de conformité et de continuité de service imposent une approche distribuée.
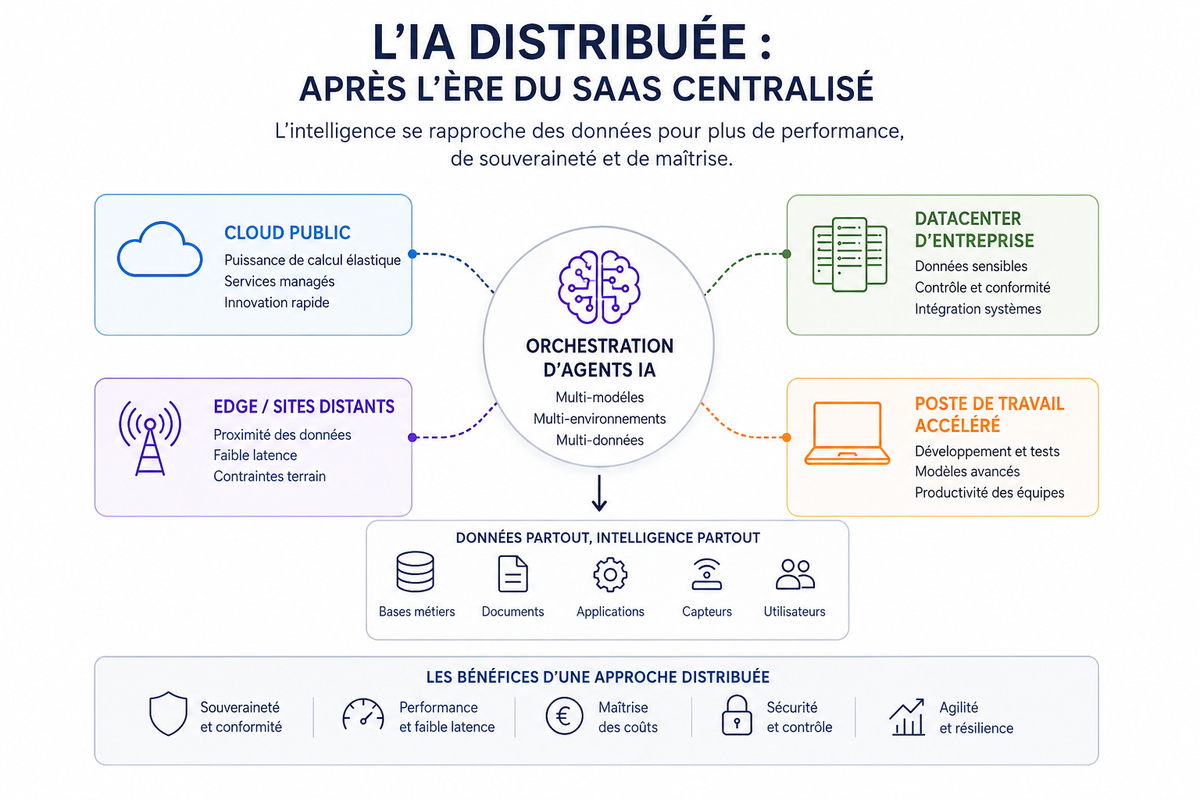
L’IA ne remplace donc pas le cloud. Elle oblige à repenser son rôle.
Le cloud reste indispensable pour entraîner de grands modèles, accéder à des capacités massives de calcul, bénéficier de services avancés et accélérer l’innovation. Mais il n’est plus nécessairement le lieu unique d’exécution de l’intelligence. Il devient une composante d’un continuum qui va du cloud public au cloud privé, du datacenter d’entreprise à l’edge, du serveur local au poste de travail accéléré. L’infrastructure IA on-premise n’est plus théorique
Ce changement n’est plus seulement conceptuel. Il se matérialise déjà dans les offres du marché. NVIDIA illustre bien ce basculement. Les nouvelles générations de puces, de serveurs et de logiciels ne visent plus seulement les hyperscalers ou les grands centres d’entraînement de modèles. Elles ciblent aussi les entreprises qui veulent exécuter des charges d’inférence, de fine-tuning, de simulation, de jumeaux numériques ou d’agents IA dans leurs propres environnements.
Avec les RTX PRO Servers basés sur l’architecture Blackwell, NVIDIA pousse l’accélération GPU dans les plateformes de datacenter d’entreprise et d’edge. Ces systèmes sont conçus pour des usages d’IA générative, d’IA agentique, de visualisation avancée, d’IA industrielle et de physical AI. Ils s’appuient sur un écosystème logiciel comprenant notamment NVIDIA AI Enterprise et NIM, ainsi que sur des intégrations avec les grands constructeurs et partenaires d’infrastructure.
La DGX Station for Windows va dans la même direction. Annoncée avec Microsoft, cette station repose sur le GB300 Grace Blackwell Ultra Desktop Superchip et vise à apporter une capacité IA de niveau datacenter dans l’environnement Windows d’entreprise. Sa disponibilité est annoncée pour le quatrième trimestre 2026. Elle ne constitue donc pas encore un déploiement massif, mais le signal est clair : l’IA d’entreprise ne sera pas uniquement consommée depuis le cloud.
Cette évolution ne concerne pas seulement NVIDIA. AMD, Intel, Apple, les grands OEM, les hyperscalers, les fournisseurs de clouds souverains et les acteurs de l’edge avancent tous vers une même direction : rendre l’inférence IA plus locale, plus spécialisée et mieux intégrée aux contraintes opérationnelles. L’IA distribuée n’est donc pas une projection futuriste. Les briques matérielles, logicielles et d’orchestration arrivent déjà sur le marché.
Le SaaS ne disparaît pas, il change de rôle
Il serait excessif d’annoncer la fin du SaaS. Les grandes plateformes comme Salesforce, ServiceNow, Workday, Microsoft, Google, SAP ou HubSpot resteront essentielles. Mais leur rôle évolue. Dans le monde SaaS classique, l’application était souvent le centre de gravité. Elle structurait les processus, captait les données, organisait les workflows et imposait son environnement.
Dans le monde de l’IA distribuée, l’application devient aussi une source, un contexte, un point d’action ou une interface parmi d’autres. La couche stratégique se déplace au-dessus des applications, vers l’orchestration de l’intelligence. Cette couche devra connecter plusieurs systèmes, comprendre les permissions, interpréter le contexte, choisir le bon modèle, déclencher la bonne action, tracer la décision et mesurer le coût réel du traitement.
C’est un changement profond pour les directions informatiques. Pendant longtemps, elles ont géré un portefeuille d’applications. Elles devront désormais gérer une architecture d’intelligence. Acheter un SaaS ne suffira plus. Il faudra définir où résident les données, quels modèles sont utilisés, quelles charges sont exécutées dans le cloud, lesquelles restent en interne, quelles règles de sécurité s’appliquent, quels agents sont autorisés à agir et comment auditer leurs décisions. Le déplacement est simple à résumer : l’application organisait le travail numérique. L’agent IA orchestrera de plus en plus le travail entre applications.
La donnée redevient l’actif central
Cette mutation a une conséquence majeure : la donnée devient plus stratégique que jamais. Dans l’ère SaaS, deux entreprises utilisant la même application pouvaient obtenir des gains relativement comparables. Dans l’ère de l’IA, deux entreprises utilisant le même modèle peuvent produire des résultats très différents. La différence ne viendra pas seulement du modèle. Elle viendra de la qualité des données, de leur accessibilité, de leur gouvernance, de leur contextualisation et de leur intégration dans les processus métier.
C’est précisément là que l’IA distribuée prend tout son sens. Lorsque les capacités d’IA sont réparties entre cloud, datacenters, sites industriels, agences, terminaux ou postes de travail, la valeur dépend de la capacité à accéder aux bonnes données, au bon endroit, avec le bon niveau de contrôle.
Une architecture 100 % cloud peut faciliter la mutualisation des ressources et l’accès à des services puissants. Une architecture distribuée peut améliorer la réactivité, limiter certains transferts de données, répondre à des contraintes réglementaires ou rapprocher le calcul des opérations. Aucune approche n’est universellement supérieure. Le bon choix dépend du cas d’usage, du niveau de sensibilité des données, du coût, de la latence et du degré de contrôle recherché. Mais une chose ne change pas : si les données sont pauvres, fragmentées ou mal gouvernées, la valeur restera limitée. L’IA expose brutalement les silos, les doublons, les incohérences et les failles de gouvernance que les entreprises ont parfois tolérés pendant des années. La question n’est donc plus seulement de choisir les meilleurs outils d’IA. Elle consiste à rendre l’entreprise intelligible pour l’IA.
La montée des modèles ouverts accélère le mouvement
L’IA distribuée est également portée par la montée en puissance des modèles ouverts ou semi-ouverts. Llama, Mistral, Qwen, DeepSeek et d’autres familles de modèles offrent aux entreprises davantage d’options pour construire des architectures multi-modèles.
Cette dynamique ne signifie pas la fin des grands modèles propriétaires. Ils resteront indispensables pour de nombreux usages. Mais elle élargit le champ des possibles. Une entreprise peut désormais combiner plusieurs approches : un grand modèle propriétaire pour des tâches généralistes, un modèle open source fine-tuné pour un domaine spécifique, un modèle local pour des données sensibles, un modèle plus léger en edge pour des contraintes de latence, et un service cloud spécialisé pour des charges ponctuelles.
L’avenir ne sera probablement pas mono-modèle. Il sera multi-modèles. Cette diversité crée des opportunités, mais aussi de la complexité. Les entreprises devront évaluer les performances, les coûts, les risques, les licences, la sécurité, l’empreinte énergétique, la conformité et la capacité réelle de chaque modèle à répondre à un usage métier. Le choix d’un modèle ne sera plus seulement une décision technique. Il deviendra une décision d’architecture, de gouvernance et parfois de souveraineté.
Le coût de l’intelligence devient un sujet stratégique
L’autre rupture concerne l’économie de l’IT. Dans le SaaS traditionnel, les coûts étaient relativement lisibles. Une licence correspondait souvent à un utilisateur, à une fonctionnalité ou à un niveau de service. Ce modèle n’était pas parfait, mais il restait prévisible. L’IA introduit une économie plus dynamique. Les coûts dépendent du nombre de requêtes, du volume de tokens, du temps GPU, de la complexité des modèles, du nombre d’agents mobilisés, du niveau de contexte utilisé, des appels API, des traitements multimodaux ou du lieu d’exécution. Un même cas d’usage peut avoir des coûts très différents selon qu’il est exécuté dans un grand modèle propriétaire, un modèle plus léger, une infrastructure cloud, un serveur interne ou un environnement edge. C’est pourquoi le FinOps IA va devenir une discipline clé.
Après avoir appris à piloter les dépenses cloud, les entreprises devront mesurer le coût réel de l’intelligence. Combien coûte une action automatisée ? Combien coûte une analyse documentaire ? Combien coûte un agent qui interroge cinq systèmes avant de produire une recommandation ? À partir de quel volume l’infrastructure interne devient-elle rentable ? À partir de quel niveau de sensibilité la souveraineté prime-t-elle sur le coût ?
L’IA localisée peut réduire la dépendance aux API externes pour certains usages récurrents ainsi que des couts maitrisés et réduits pour les tokens. Elle peut aussi offrir une meilleure visibilité économique dans le temps. Mais elle exige des investissements, des compétences, de l’exploitation et une gouvernance technique rigoureuse. Le sujet n’est donc pas de choisir systématiquement le cloud ou le on-premise. Le sujet est de placer chaque charge d’IA au bon endroit, avec le bon modèle économique.
Le DSI devient architecte de l’intelligence distribuée
Dans ce contexte, le rôle du DSI change profondément. Il ne s’agit plus seulement de sélectionner des applications, négocier des contrats SaaS, sécuriser des infrastructures et garantir la disponibilité des systèmes. Il s’agit de concevoir une architecture d’intelligence capable d’exploiter des données réparties, d’orchestrer plusieurs modèles, de maîtriser les coûts, de garantir la sécurité et de contrôler les agents autonomes.
Cinq priorités émergent.
La première est la gouvernance des données. Sans données fiables, accessibles et maîtrisées, l’IA restera limitée à des démonstrations isolées. La deuxième est la stratégie multi-modèles, afin d’éviter une dépendance excessive à un seul fournisseur tout en conservant une cohérence d’ensemble. La troisième est l’architecture hybride. Chaque charge d’IA devra être placée au bon endroit : cloud public, cloud privé, infrastructure souveraine, serveur interne, edge ou terminal. La quatrième est le FinOps IA. Les organisations devront mesurer le coût de l’intelligence avec la même rigueur que le coût du cloud. La cinquième est la gouvernance des agents. Plus les systèmes seront capables d’agir, plus il faudra contrôler leurs permissions, tracer leurs décisions, limiter leur périmètre d’action et auditer leur comportement.
La vraie question : où doit vivre l’intelligence ?
La question stratégique des prochaines années ne sera donc plus seulement : quel SaaS devons-nous acheter ? Elle deviendra : où doit vivre l’intelligence de l’entreprise ? Dans le cloud public, lorsqu’il faut de la puissance, de l’élasticité et un accès rapide à des services avancés. Dans un cloud souverain, lorsque les contraintes réglementaires ou politiques l’imposent. Dans un datacenter interne, lorsque la donnée est critique ou que la maîtrise est prioritaire. En edge, lorsque la latence, la continuité de service ou le contexte terrain sont déterminants. Sur un poste de travail accéléré, lorsque les équipes doivent développer, tester ou exécuter localement des modèles avancés. Il n’y aura pas de réponse unique. C’est précisément le point.
L’ère qui s’ouvre ne sera pas celle d’un modèle centralisé remplaçant tous les autres. Elle sera celle d’une intelligence distribuée, orchestrée, gouvernée et mesurée. Le SaaS a permis de standardiser et d’accélérer la transformation numérique. L’IA distribuée oblige désormais à la reconfigurer.
Après quinze ans passés à déplacer les applications vers le cloud, les entreprises doivent apprendre à placer l’intelligence au bon endroit. C’est cette capacité qui déterminera demain leur compétitivité, leur résilience et leur souveraineté numérique.